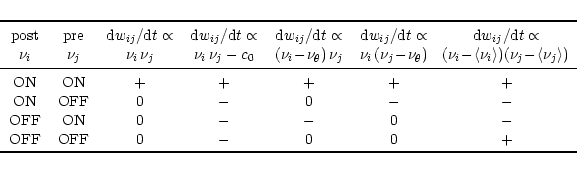In order to prepare the ground for a thorough analysis of spike-based learning rules in Section 10.3 we will first review the basic concepts of correlation-based learning in a firing rate formalism.
In order to find a mathematically formulated learning rule based on Hebb's
postulate we focus on a single synapse with efficacy wij that transmits
signals from a presynaptic neuron j to a postsynaptic neuron i. For the
time being we content ourselves with a description in terms of mean firing
rates. In the following, the activity of the presynaptic neuron is denoted by
![]() and that of the postsynaptic neuron by
and that of the postsynaptic neuron by ![]() .
.
There are two aspects in Hebb's postulate that are particularly important, viz. locality and cooperativity. Locality means that the change of the synaptic efficacy can only depend on local variables, i.e., on information that is available at the site of the synapse, such as pre- and postsynaptic firing rate, and the actual value of the synaptic efficacy, but not on the activity of other neurons. Based on the locality of Hebbian plasticity we can make a rather general ansatz for the change of the synaptic efficacy,
The second important aspect of Hebb's postulate, cooperativity, implies that
pre- and postsynaptic neuron have to be active simultaneously for a
synaptic weight change to occur. We can use this property to learn something
about the function F. If F is sufficiently well-behaved, we can
expand F in a Taylor series about
![]() =
= ![]() = 0,
= 0,
The simplest choice for our function F is to fix ccorr2 at a positive constant and to set all other terms in the Taylor expansion to zero. The result is the prototype of Hebbian learning,
The dependence of F on the synaptic efficacy wij is a natural consequence of the fact that wij is bounded. If F was independent of wij then the synaptic efficacy would grow without limit if the same potentiating stimulus is applied over and over again. A saturation of synaptic weights can be achieved, for example, if the parameter ccorr2 in Eq. (10.2) tends to zero as wij approaches its maximum value, say wmax = 1, e.g.,
Hebb's original proposal does not contain a rule for a decrease of synaptic weights. In a system where synapses can only be strengthened, all efficacies will finally saturate at their upper maximum value. An option of decreasing the weights (synaptic depression) is therefore a necessary requirement for any useful learning rule. This can, for example, be achieved by weight decay, which can be implemented in Eq. (10.2) by setting
Another interesting aspect of learning rules is competition. The idea is that synaptic weights can only grow at the expense of others so that if a certain subgroup of synapses is strengthened, other synapses to the same postsynaptic neuron have to be weakened. Competition is essential for any form of self-organization and pattern formation. Practically, competition can be implemented in simulations by normalizing the sum of all weights converging onto the same postsynaptic neuron (Miller and MacKay, 1994); cf. Section 11.1.3. Though this can be motivated by a limitation of common synaptic resources such a learning rule violates locality of synaptic plasticity. On the other hand, competition of synaptic weight changes can also be achieved with purely local learning rules (Kistler and van Hemmen, 2000a; Kempter et al., 2001; Oja, 1982; Song et al., 2000).
Equation (10.6) is just one possibility to specify rules for the growth and decay of synaptic weights. In the framework of Eq. (10.2), other formulations are conceivable; cf. Table 10.1. For example, we can define a learning rule of the form
A particularly interesting case from a theoretical point of view is the choice
![]() (wij) = wij, i.e.,
(wij) = wij, i.e.,
Let us now turn to a learning rule where synaptic changes are `gated' by the
presynaptic activity ![]() . The corresponding equation has the same form as
Eq. (10.7) except that the role of pre- and postsynaptic firing rate are
exchanged,
. The corresponding equation has the same form as
Eq. (10.7) except that the role of pre- and postsynaptic firing rate are
exchanged,
For ![]() < 0, the correlation term has a negative sign and the learning rule
(10.9) gives rise to anti-Hebbian plasticity, which has an interesting
stabilizing effect on the postsynaptic firing rate. If the presynaptic firing
rates are kept constant, the postsynaptic firing rate
< 0, the correlation term has a negative sign and the learning rule
(10.9) gives rise to anti-Hebbian plasticity, which has an interesting
stabilizing effect on the postsynaptic firing rate. If the presynaptic firing
rates are kept constant, the postsynaptic firing rate ![]() will finally
converge to the reference value
will finally
converge to the reference value
![]() . To see why let us consider a
simple rate neuron with output rate
. To see why let us consider a
simple rate neuron with output rate
![]() = g(
= g(![]() wij
wij![]() ). For
). For
![]() <
< ![]() , all synapses are strengthened (
dwij/dt > 0 for all j) and the overall input strength
hi =
, all synapses are strengthened (
dwij/dt > 0 for all j) and the overall input strength
hi = ![]() wij
wij![]() is increasing. Since g is a monotonously growing function of hi,
the output rate tends to
is increasing. Since g is a monotonously growing function of hi,
the output rate tends to
![]() . On the other hand, if
. On the other hand, if
![]() >
> ![]() , all synaptic efficacies decrease and so does
, all synaptic efficacies decrease and so does ![]() . Hence,
. Hence,
![]() =
= ![]() is a globally attractive fixed point of the postsynaptic
activity. Some of the detailed spike-based learning rule, to be discussed
below, will show a similar stabilization of the postsynaptic activity.
is a globally attractive fixed point of the postsynaptic
activity. Some of the detailed spike-based learning rule, to be discussed
below, will show a similar stabilization of the postsynaptic activity.
Sejnowski and Tesauro (1989) have suggested a learning rule of the form
All of the above learning rules had
cpre2 = cpost2 = 0. Let us now consider
a nonzero quadratic term
cpost2 = - ![]() wij. We take
ccorr2 =
wij. We take
ccorr2 = ![]() > 0 and set all other parameters to zero. The learning rule
> 0 and set all other parameters to zero. The learning rule
Higher terms in the expansion on the right-hand side of Eq. (10.2) lead to more intricate plasticity schemes. As an example, let us consider a generalization of the presynaptic gating rule in Eq. (10.9)
Some experiments (Artola et al., 1990; Ngezahayo et al., 2000; Artola and Singer, 1993)
suggest that the function ![]() should look similar to that sketched in Fig. 10.5. Synaptic
weights do not change as long as the postsynaptic activity stays below a
certain minimum rate,
should look similar to that sketched in Fig. 10.5. Synaptic
weights do not change as long as the postsynaptic activity stays below a
certain minimum rate, ![]() . For moderate levels of postsynaptic
excitation, the efficacy of synapses activated by presynaptic input is decreased. Weights are increased only if the level of postsynaptic
activity exceeds a second threshold,
. For moderate levels of postsynaptic
excitation, the efficacy of synapses activated by presynaptic input is decreased. Weights are increased only if the level of postsynaptic
activity exceeds a second threshold,
![]() . The change of weights is
restricted to those synapses which are activated by presynaptic input, hence
the `gating' factor
. The change of weights is
restricted to those synapses which are activated by presynaptic input, hence
the `gating' factor ![]() in Eq. (10.12).
By arguments completely analogous to the ones made above for the
presynaptically gated rule, we can convince ourselves
that the postsynaptic rate has a fixed point
at
in Eq. (10.12).
By arguments completely analogous to the ones made above for the
presynaptically gated rule, we can convince ourselves
that the postsynaptic rate has a fixed point
at
![]() . For the form of the function shown
in Fig.10.5
this fixed point is unstable.
In order to avoid that the postsynaptic firing rate
blows up or decays to zero, it is therefore
necessary to turn
. For the form of the function shown
in Fig.10.5
this fixed point is unstable.
In order to avoid that the postsynaptic firing rate
blows up or decays to zero, it is therefore
necessary to turn
![]() into an adaptive variable
(Bienenstock et al., 1982).
We will come back
to the BCM rule towards the end of this chapter.
into an adaptive variable
(Bienenstock et al., 1982).
We will come back
to the BCM rule towards the end of this chapter.
![\hbox{\hspace{20mm} \includegraphics[width=60mm]{Figs-ch-Hebbrules/Fig8.eps} }](img1620.gif) |
© Cambridge University Press
This book is in copyright. No reproduction of any part
of it may take place without the written permission
of Cambridge University Press.