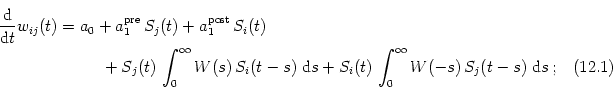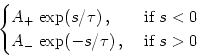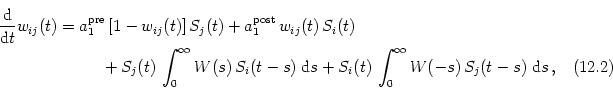We have seen in Section 12.1 that learning rules with an asymmetric learning window can selectively strengthen those synapses that reliably transmit spikes at the earliest possible time before the postsynaptic neuron gets activated by a volley of spikes from other presynaptic neurons. This mechanism may be relevant to speed up the information processing in networks that contain several hierarchically organized layers.
Here we are going to discuss a related phenomenon that may be equally important in networks that are based on a time-coding paradigm, i.e., in networks where information is coded in the precise firing time of individual action potentials. We show that an asymmetric learning window can selectively strengthen synapses that deliver precisely timed spikes at the expense of others that deliver spikes with a broad temporal jitter. This is obviously a way to reduce the noise level of the membrane potential and to increase the temporal precision of the postsynaptic response (Kistler and van Hemmen, 2000a).
We consider a neuron i that receives spike input from N presynaptic
neurons via synapses with weights wij,
1![]() j
j![]() N. The membrane
potential ui(t) is described by the usual SRM0 formalism with response
kernels
N. The membrane
potential ui(t) is described by the usual SRM0 formalism with response
kernels ![]() and
and ![]() , and the last postsynaptic firing time
, and the last postsynaptic firing time
![]() , i.e.,
, i.e.,
| ui(t) = |
(12.1) |
Postsynaptic spikes are triggered according to the escape-noise model
(Section 5.3) with a rate ![]() that is a nonlinear function
of the membrane potential,
that is a nonlinear function
of the membrane potential,
| (12.2) |
Presynaptic spike trains are described by inhomogeneous Poisson processes with
a time-dependent firing intensity ![]() (t). More specifically, we consider a
volley of spikes that reaches the postsynaptic neuron approximately at time
t0. The width of the volley is determined by the time course of the firing
intensities
(t). More specifically, we consider a
volley of spikes that reaches the postsynaptic neuron approximately at time
t0. The width of the volley is determined by the time course of the firing
intensities ![]() . For the sake of simplicity we use bell-shaped intensities
with a width
. For the sake of simplicity we use bell-shaped intensities
with a width ![]() centered around t0. The width
centered around t0. The width ![]() is a
measure for the temporal precision of the spikes that are conveyed via synapse
i. The intensities are normalized so that, on average, each presynaptic
neuron contributes a single action potential to the volley.
is a
measure for the temporal precision of the spikes that are conveyed via synapse
i. The intensities are normalized so that, on average, each presynaptic
neuron contributes a single action potential to the volley.
Synaptic plasticity is implemented along the lines of Section ![]() . Synaptic weights change whenever presynaptic spikes
arrive or when postsynaptic action potentials are triggered,
. Synaptic weights change whenever presynaptic spikes
arrive or when postsynaptic action potentials are triggered,
![\centerline{\includegraphics[width=6cm]{Figs-ch-hebbcode/exp_window.eps}}](img1967.gif) |
In addition to the Hebbian term we also take advantage of the non-Hebbian
terms
a1pre and
a1post in order to ensure that the
postsynaptic firing rate stays within certain bounds. More precisely, we use
0 < a1pre ![]() 1 and
-1
1 and
-1 ![]() a1post < 0. A positive
value for
a1pre leads to growing synapses even if only the
presynaptic neuron is active. This effect will bring the neuron back to
threshold even if all synaptic weights were strongly depressed. A small
negative value for
a1post, on the other hand, leads to a
depression of the synapse, if the postsynaptic neuron is firing at an
excessively high rate. Altogether, the non-Hebbian terms keep the neuron at
its operating point.
a1post < 0. A positive
value for
a1pre leads to growing synapses even if only the
presynaptic neuron is active. This effect will bring the neuron back to
threshold even if all synaptic weights were strongly depressed. A small
negative value for
a1post, on the other hand, leads to a
depression of the synapse, if the postsynaptic neuron is firing at an
excessively high rate. Altogether, the non-Hebbian terms keep the neuron at
its operating point.
Apart from the postsynaptic firing rate we also want to have individual
synaptic weights to be restricted to a finite interval, e.g., to [0, 1]. We
can achieve this by introducing a dependence of the parameters in Eqs.
(12.3) and (12.4) on the actual value of the
synaptic weight. All terms leading to potentiation should be proportional to
(1 - wij) and all terms leading to depression to wij; cf. Section ![]() . Altogether we have
. Altogether we have
We have seen in Section 11.2.1 that the evolution of synaptic
weights depends on correlations of pre- and postsynaptic spike trains on the
time scale of the learning window. In order to calculate this correlation we
need the joint probability density for pre- and postsynaptic spikes (`joint
firing rate'),
![]() (t, t'); cf. Eq. (11.48). We have already
calculated the joint firing rate for a particularly simple neuron model, the
linear Poisson neuron, in Section 11.2.2. Here, however, we
are interested in nonlinear effects due to the neuronal firing threshold. A
straightforward calculation of spike-spike correlations is therefore no longer
possible. Instead we argue, that the spike correlation of the postsynaptic and
a single presynaptic neuron can be neglected in neurons that receive synaptic
input from many presynaptic cells. In this case, the joint firing rate is just
the product of pre- and postsynaptic firing intensities,
(t, t'); cf. Eq. (11.48). We have already
calculated the joint firing rate for a particularly simple neuron model, the
linear Poisson neuron, in Section 11.2.2. Here, however, we
are interested in nonlinear effects due to the neuronal firing threshold. A
straightforward calculation of spike-spike correlations is therefore no longer
possible. Instead we argue, that the spike correlation of the postsynaptic and
a single presynaptic neuron can be neglected in neurons that receive synaptic
input from many presynaptic cells. In this case, the joint firing rate is just
the product of pre- and postsynaptic firing intensities,
| (12.4) |
It thus remains to determine the postsynaptic firing time distribution given
the presynaptic spike statistics. As we have already discussed in
Section 11.2.2 the output spike train is the result of a
doubly stochastic process (Bartlett, 1963; Cox, 1955) in the sense that first
presynaptic spike trains are produced by inhomogeneous Poisson processes so
that the membrane potential is in itself a stochastic process. In a second
step the output spike train is generated from a firing intensity that is a
function of the membrane potential. Though the composite process is not
equivalent to an inhomogeneous Poisson process, the output spike train can be
approximated by such a process with an intensity that is given by the
expectation of the rate ![]() with respect to the input statistics
(Kistler and van Hemmen, 2000a),
with respect to the input statistics
(Kistler and van Hemmen, 2000a),
Due to refractoriness, the neuron cannot fire two spikes directly one after the other; an effect that is clearly not accounted for by a description in terms of a firing intensity as in Eq. (12.7). A possible way out is to assume that the afterpotential is so strong that the neuron can fire only a single spike followed by a long period of silence. In this case we can focus on the probability density pfirst(t) of the first postsynaptic spike which is given by the probability density to find a spike at t times the probability that there was no spike before, i.e.,
| pifirst(t) = |
(12.6) |
Given the statistics of the presynaptic volley of action potentials we are now
able to calculate the expected firing intensity
![]() (t) of the
postsynaptic neuron and hence the firing time distribution
pfirst(t) of the first action potential that will be triggered by
the presynaptic volley. In certain limiting cases, explicit expressions for
pfirst(t) can be derived; cf. Fig. 12.5 (see
Kistler and van Hemmen (2000a) for details).
(t) of the
postsynaptic neuron and hence the firing time distribution
pfirst(t) of the first action potential that will be triggered by
the presynaptic volley. In certain limiting cases, explicit expressions for
pfirst(t) can be derived; cf. Fig. 12.5 (see
Kistler and van Hemmen (2000a) for details).
![\begin{minipage}{0.48\textwidth}
{\bf A}\\
\includegraphics[width=0.9\textwid...
...ludegraphics[width=0.9\textwidth,trim=15 0 0 0]{poisson_b.ps.gz}
\end{minipage}](img1974.gif) |
In the limiting case of many presynaptic neurons and strong refractoriness the joint firing rate of pre- and postsynaptic neuron is given by
| (12.7) |
A given combination of pre- and postsynaptic firing times will result in a, say, potentiation of the synaptic efficacy and the synaptic weight will be increased whenever this particular stimulus is applied. However, due to the soft bounds that we have imposed on the weight dynamics, the potentiating terms become less and less effective as the synaptic weight approaches its upper bound at wij = 1, because all terms leading to potentiation are proportional to (1 - wij). On the other hand, terms that lead to depression become increasingly effective due to their proportionality to wij. At some point potentiation and depression balance each other so that a fixed point for the synaptic weight is reached.
Figure 12.6 shows the stationary synaptic weight as a
function of the firing time statistics given in terms of the temporal jitter
![]() of pre- and postsynaptic spikes and their relative firing time. For
small values of
of pre- and postsynaptic spikes and their relative firing time. For
small values of ![]() , that is, for precisely timed spikes, we recover the
shape of the learning window: The synaptic weight saturates close to its
maximum value if the presynaptic spikes arrive before the postsynaptic neuron
is firing. If the timing is the other way round, the weight will be
approximately zero. For increasing levels of noise in the firing times this
relation is smeared out and the weight takes an intermediate value that is
determined by non-Hebbian terms rather than by the learning window.
, that is, for precisely timed spikes, we recover the
shape of the learning window: The synaptic weight saturates close to its
maximum value if the presynaptic spikes arrive before the postsynaptic neuron
is firing. If the timing is the other way round, the weight will be
approximately zero. For increasing levels of noise in the firing times this
relation is smeared out and the weight takes an intermediate value that is
determined by non-Hebbian terms rather than by the learning window.
![\begin{minipage}[t]{0.48\textwidth}
{\bf A}\\
\includegraphics[width=\textwid...
...\\
\includegraphics[width=0.8\textwidth]{stat_weights_b.ps.gz}
\end{minipage}](img1978.gif) |
We have seen that the stationary value of the synaptic weight is a function of the statistical properties of pre- and postsynaptic spike train. The synaptic weights, on the other hand, determine the distribution of postsynaptic firing times. If we are interested in the synaptic weights that are produced by a given input statistics, we thus have to solve a self-consistency problem which can be done numerically by using explicit expressions for the firing time distributions derived along the lines sketched above.
Figure 12.7 shows an example of a neuron that receives spike
input from two groups of presynaptic neurons. The first group is firing
synchronously with a rather high temporal precision of
![]() = 0.1. The
second group is also firing synchronously but with a much broader jitter of
= 0.1. The
second group is also firing synchronously but with a much broader jitter of
![]() = 1. (All times are in units of the membrane time constant.) The spikes
from both groups together form the spike volley that impinges on the
postsynaptic neuron and induce changes in the synaptic weights. After a couple
of these volleys have hit the neuron the synaptic weights will finally settle
at their fixed point. Figure Fig. 12.7A shows the resulting weights
for synapses that deliver precisely timed spikes together with those of the
poorly timed group as a function of the neuronal firing threshold.
= 1. (All times are in units of the membrane time constant.) The spikes
from both groups together form the spike volley that impinges on the
postsynaptic neuron and induce changes in the synaptic weights. After a couple
of these volleys have hit the neuron the synaptic weights will finally settle
at their fixed point. Figure Fig. 12.7A shows the resulting weights
for synapses that deliver precisely timed spikes together with those of the
poorly timed group as a function of the neuronal firing threshold.
As is apparent from Fig. 12.7A there is a certain domain for the
neuronal firing threshold (
![]()
![]() 0.25) where synapses that convey
precisely timed spikes are substantially stronger than synapses that deliver
spikes with a broad temporal jitter. The key for an understanding of this
result is the normalization of the postsynaptic firing rate by non-Hebbian
terms in the learning equation.
0.25) where synapses that convey
precisely timed spikes are substantially stronger than synapses that deliver
spikes with a broad temporal jitter. The key for an understanding of this
result is the normalization of the postsynaptic firing rate by non-Hebbian
terms in the learning equation.
The maximum value of the membrane potential if all presynaptic neurons deliver
one precisely timed spike is
umax = 1. The axis for the firing
threshold in Fig. 12.7 therefore extends from 0 to 1. Let us consider
high firing thresholds first. For
![]()
![]() 1 the postsynaptic
neuron will reach its firing threshold only, if all presynaptic spikes arrive
almost simultaneously, which is rather unlikely given the high temporal jitter
in the second group. The probability that the postsynaptic neuron is firing an
action potential therefore tends to zero as
1 the postsynaptic
neuron will reach its firing threshold only, if all presynaptic spikes arrive
almost simultaneously, which is rather unlikely given the high temporal jitter
in the second group. The probability that the postsynaptic neuron is firing an
action potential therefore tends to zero as
![]()
![]() 1; cf. Fig.
1; cf. Fig. ![]() C. Every time
when the volley fails to trigger the neuron the weights are increased due to
presynaptic potentiation described by
a1pre > 0. Therefore,
irrespective of their temporal precision all synapses will finally reach an
efficacy that is close to the maximum value.
C. Every time
when the volley fails to trigger the neuron the weights are increased due to
presynaptic potentiation described by
a1pre > 0. Therefore,
irrespective of their temporal precision all synapses will finally reach an
efficacy that is close to the maximum value.
On the other hand, if the firing threshold is very low, then a few presynaptic spikes suffice to trigger the postsynaptic neuron. Since the neuron can fire only a single action potential as a response to a volley of presynaptic spikes the neuron will be triggered by earliest spikes; cf. Section 12.1. The early spikes however are mostly spikes from presynaptic neurons with a broad temporal jitter. The postsynaptic neuron has therefore already fired its action potential before the spikes from the precise neurons arrive. Synapses that deliver precisely timed spikes are hence depressed, whereas synapses that deliver early but poorly timed spikes are strengthened.
For some intermediate values of the firing threshold, synapses that deliver precisely timed spikes are strengthened at the expense of the other group. If the firing threshold is just high enough so that a few early spikes from the poorly timed group are not able to trigger an action potential then the neuron will be fired most of the time by spikes from the precise group. These synapses are consistently strengthened due to the Hebbian learning rule. Spikes from the other group, however, are likely to arrive either much earlier or after the neuron has already fired so that the corresponding synapses are depressed.
A neuron that gets synaptic input predominantly from neurons that fire with a
high temporal precision will also show little temporal jitter in its firing
time relative to its presynaptic neurons. This is illustrated in Fig. ![]() B which gives the precision
B which gives the precision ![]() t of the postsynaptic firing
time as a function of the firing threshold. The curve exhibits a clear peak
for firing thresholds that favor `precise' synapses. The precision of the
postsynaptic firing time shows similarly high values in the high firing
threshold regime. Here, however, the overall probability
t of the postsynaptic firing
time as a function of the firing threshold. The curve exhibits a clear peak
for firing thresholds that favor `precise' synapses. The precision of the
postsynaptic firing time shows similarly high values in the high firing
threshold regime. Here, however, the overall probability
![]() for the neuron to reach the threshold is very low
(Fig. 12.7C). In terms of a `coding efficiency' defined by
for the neuron to reach the threshold is very low
(Fig. 12.7C). In terms of a `coding efficiency' defined by
![]() /
/![]() t there is thus a clear optimum for the firing
threshold near
t there is thus a clear optimum for the firing
threshold near
![]() = 0.25 (Fig. 12.7D).
= 0.25 (Fig. 12.7D).
![\begin{minipage}[t]{0.48\textwidth}
{\bf A}\\
\centerline{\includegraphics[wi...
...ncludegraphics[width=\textwidth, trim=15 0 0
0]{result_d.ps.gz}} \end{minipage}](img1983.gif) |
© Cambridge University Press
This book is in copyright. No reproduction of any part
of it may take place without the written permission
of Cambridge University Press.